Container Orchestration from Container Orchestration
Medium post by Rob about Kubernetes, finance risk workloads, and sonifying a container cluster.
_Archive extraction note: sourced from the public Medium RSS feed for @robertdseidman._
This is an example of container orchestration demonstrated through... container orchestration.

I mean this label of "orchestration" quite literally; perhaps it's not all that much of a coincidence to use the original definition of the word that was selected to represent the more technologically abstract concept by applying the definition literally. We stumbled upon this poetically elegant coincidence as a clever way to educate the less-technically proficient on the virtues of Kubernetes and the potential it has to revolutionize the financial risk management business. In other words, it's been quite useful to deploy an actual orchestra to describe what orchestration actually is.
Let's explain how we got here by starting at the beginning, seeing how many kubectl puns we can make along the way.
Containerization
During the day, I spend my time running an innovation team. When interviewing candidates seeking to join our innovation team in the past, I'll sometimes ask them to describe the process of how to calculate something like VaR (Value at Risk). It's quite insightful to understand where their expertise lies based on where in the stack they start the explanation. Some may begin with telling you to sort the scenario results by magnitude, others with more implementation experience might begin their answer with comments about data model or data vendor choices that would be needed to populate the models. I have yet to receive an answer in line with what I'm seeking, and will usually have to quote Carl Sagan who once famously began an episode of COSMOS with, "If you wish to make an apple pie from scratch, you must first invent the universe." While a bit hyperbolic of an analogy to apply to our use case, it's meant to undermine the candidate's implicit assumption that the computational infrastructure - the "computers", be they human or silicon - are out of scope of our conversation.
Note: Since most use cases where we're looking to calculate something like VaR require a timelier rollout than "before the eventual heat death of the universe", it's a bit more practical to only consider the case where we're using computers (though I will concede that case studies of meat-based implementations of modern computations are another area of fascination of mine).
As with any complex implementation, this begets a conversation with IT about the hardware makes and models required to support it, as well as any other dependent software such as libraries or operating systems. Making sure you get everything right requires a lot of due diligence whose decisions and responsibilities are often stratified over multiple corporate silos like IT and infrastructure management, risk management and functional users, and sometimes a business users who may also be out of the loop on the methodology and the math.
Containers enable portability through standardization. Containers come in a standard size so they can be deployed anywhere - boats, trucks, and even trains to leverage "legacy infrastructure". Those trying to sell their wares don't also have to own their own shipping vessels; if they get it into a container, it'll arrive at its destination. So for those playing at home, yes, we're talking about physical containers but the paradigm and benefits are the same making the word choice apt. Just like its real-world counterpart, if you can get your software in a container, it can run anywhere containers are supported, lending credence to our aforementioned interview candidate's answer. Just focus on the business case, and let the infrastructure be somebody else's problem. Shipping - another wisely named action - code becomes simpler, and a whole new paradigm of load balancing, in place updates and upgrades, and redundancy opens up with the potential to radically redesign devOps workflows.

Containers enabling portability through standardization
Of course as this technology is a new paradigm, it requires a fundamental shift in the way you think about your architecture and exec on your workflows
Making the Leap from Container to Microservice
You can put pretty much anything you want into a container from a software perspective. You can stick a giant monolithic software installation inside, but this doesn't imply it's necessarily going to run more efficiently than an installation on a dedicated resource. It might be easier to ship, but whatever is in that box is the same thing that's always been there. The natural evolution of the use case is to re-architect it into microservices, thereby making more efficient use of containers.
There's no one right answer on how to decompose an application into microservices and doing so can be a little bit more of an art than a science. Maybe the database gets moved off of the container to take advantage of load balancing so multiple containers can all access the same data, and redundancy to ensure that at least one copy of the database is always available. Perhaps the database exists on a file system and the application spins up a database server container and issues a query in a single line of code. You can start to get really smart about your resource consumption, with both software and hardware only becoming instantiated when needed. As most public cloud providers charge by the hour, this becomes an opportunity to not only increase performance by leveraging more hardware but to also decrease costs by only using that hardware when needed.
Simulation Microservices
At my aforementioned day job, we create microservices from our legacy software. One such microservice that's already yielded tremendous value is our simulation-engine microservice. The most computationally hungry step in a risk management workflow, our service performs all of the cashflow projections, scenario analysis, and financial security modeling leveraging container infrastructure. Most financial institutions are beholden to regulation which seeks to make sure these institutions stay solvent under worst case scenarios, but to answer that question, you first have to expose what the worst-case scenario is and what your global book of holdings might do under that scenario. Mathematically, the best way we have of predicting the future is to build a distribution of probabilities - a kind of hurricane cone of uncertainty - of where a portfolio might be at some point in the future leveraging some knowledge of the past and how things tend to behave in conjunction with another (e.g. a gaussian copula based Monte Carlo simulation).
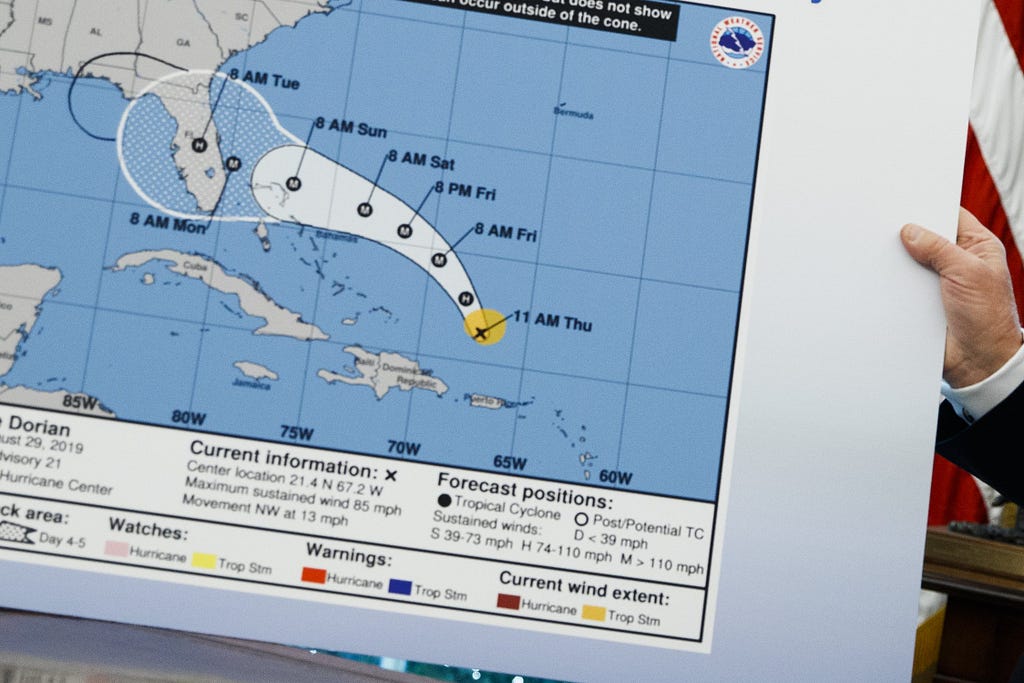
The hurricane "cone of uncertainty", or a more familiar way of intuiting confidence intervals.
These calculations, when looked at the cumulative global set across all financial institutions, are likely some of the largest use cases for the sum of planet Earth's computations alongside nuclear bomb simulation and weather forecasting (also due to their monte-carlo nature). The currently accepted methodology is for firms to build their own supercomputers, install the software, warm it up and wait for the simulation to complete. When dealing with such extreme scale, it becomes a bit onerous to have to double or triple the size of the grid just to be able to keep up with federally mandated regulatory calculations.
So what if we took those massive calculations and broke them down into more granular, manageable pieces which can fit on standard container sizes offered by various public and private cloud providers? Suddenly, the cost of infrastructure isn't such a drain on your IT budget as the need for dedicated hardware, and the people and resources to manage them and keep them humming 24/7/365, are no longer required. Massive batches can be autoscaled across figuratively unlimited hardware, for lower cost than ever before.
Cluster Reporting
We've been internally operating our offering in production for over a year now, eating our own dogfood so to speak, which was what allowed us to replace our own legacy infrastructure with a much more cost-efficient model. A number of innovative cloud tools have emerged to help development teams support the swarm of containers that are coming to life and evaporating upon completion, but it wasn't until we created our own version of a reporting tool to suit our unique application and annotate what was going on a set of hardware that we were able to evangelize and convert those individuals not directly involved with devOps to this new way of thinking. Simply put: we needed to "see" the cluster.
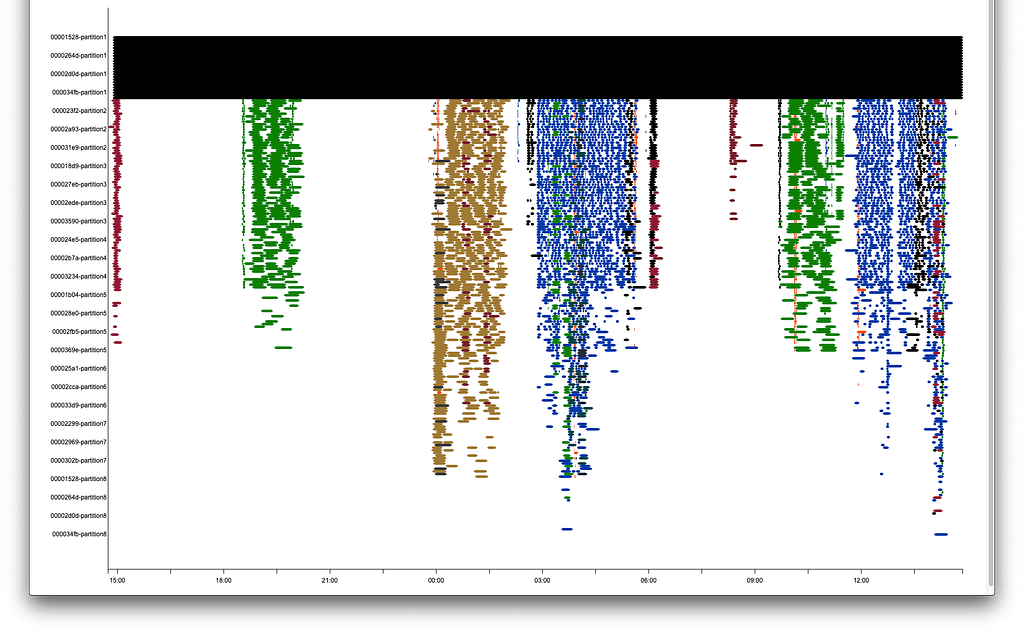
A view of our Kubernetes cluster jobs
Each dot or dash is a proxy for one container, housing one instance of our financial modeling software. The y-axis represents the total available hardware provisioned for the time period (we're considering a fixed set of hardware in this example as a more dynamically inflating and contracting set of resources would resemble the diagonal of a crossword puzzle). The x-axis represents time, or in this case a 24 hour period. Each color represents either a different client, or a different type of batch run, depending on what the service is being used for. When we started to show off this report-forward thinking as it may be - one thing began to become clear. Each of the groupings of dots and dashes representing a batch run as a vertical line, would have been horizontal line on dedicated resources using the previous methodology.
It was a very intuitive way to realize the value proposition of what we had created. We had taken huge client batches and reduced their duration from hours to minutes, on hardware that was much cheaper to support. That's two separate dimensions of innovation on the status quo, each approaching an order of magnitude of improvement on the way it was done before.
The Soothing Sounds of Kubernetes
Still with me? Great. Here's where things go off the deep end.
So if the above visualization represents a way to "see" the cluster, what if you wanted to "hear" the cluster?
We then took the results of the visualization and converted it to a MIDI file, effectively converting the picture to a digital player piano roll. Taking that a step further, we can convert the colors to different instruments in order to attach a unique timbre to preserve that additional dimension of information.
I caution those would-be listeners; at best you could describe the resulting sounds (as we're loathe to call it 'music') as Avant-Garde. You can click here to hear an example of this, though fair warning - it's quite horrible. As MIDI is directly translatable into musical notation or score, we can see what that music should look like.
And thus, I leave you with container orchestration:

What our kubernetes cluster sounds like.
Source
- Original Medium URL: https://medium.com/@robertdseidman/container-orchestration-from-container-orchestration-8be23708cf67
- Published: June 25, 2020
- Medium updated timestamp: 2020-06-26T12:34:44.355Z
- External media link from original post: https://sia-images.s3.us-east.cloud-object-storage.appdomain.cloud/soothing_sounds_of_kubernetes.midi